一、引言:DeepSeek的崛起
在AI模型竞争白热化的今天,DeepSeek这个名字正变得越来越响亮。它不是OpenAI,也不是Meta,但靠着一股“硬核极客”精神,正在用技术重新定义行业规则。
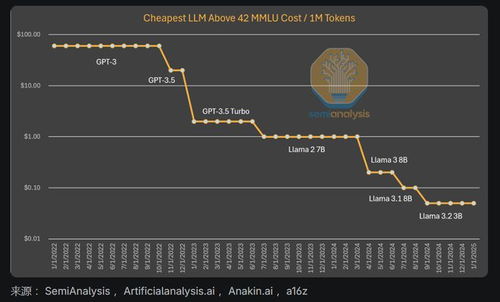
就在前几天,DeepSeek公开了其V3版本的技术细节和运营数据,震撼了整个AI圈。他们不仅把参数数量减少了60%,还让API价格低至1元/百万Token——这简直是给中小开发者送福利。
二、技术拆解:V3的秘密武器
DeepSeek V3之所以能实现如此惊人的突破,靠的是几项核心技术:
- MLA(多头潜在注意力)架构:通过降秩KV矩阵压缩模型规模
- MoE(混合专家模型)架构:动态调用最合适的子模型,提升推理效率
- FP8低精度训练:降低计算资源消耗
- MTP多Token预测:一次生成多个输出词,加快响应速度
这些技术并非简单堆砌,而是深度协同。比如MLA与MoE结合后,既保证了性能不下降,又大幅降低了模型复杂度。而强化学习的应用,更是让训练效率提升了数倍。
三、成本分析:每天竟只要$87K?!
我们来算一笔账:
GPU租赁成本:2美元/小时
日均节点占用:约226.75个
日总成本:≈87,072美元
再来看看收入端:
单日总收入:562,027美元
净利润:≈474,955美元!
换句话说,DeepSeek不仅控制住了成本,还实现了近50万美元的利润。这在AI行业是非常罕见的成绩。

四、行业影响:AI平民化时代来临
过去,AI模型是巨头的游戏。但现在,DeepSeek用V3/R1告诉所有人:开源、高效、低成本的模型也能做得很好。
更重要的是,这种“极致性价比”策略正在让更多中小企业和独立开发者有机会使用顶级AI能力。比如在设备运维、知识管理等领域,已经有企业开始尝试用DeepSeek做智能化升级。
有业内人士评价说:“DeepSeek像是AI界的Redmi手机,把高端配置拉到了人人可用的价格。”
五、未来展望:DeepSeek还能走多远?
从V2到V3,再到R1,DeepSeek每一步都在打破传统认知边界。他们的技术路线图显示,接下来还将探索更多软硬件协同优化方案,甚至可能推出专为边缘计算设计的轻量版模型。
如果这种趋势持续下去,我们可以预见一个更开放、更普惠的AI生态正在形成。正如DeepSeek官方所说:“我们不做AI贵族,只做AI工匠。”


发表评论 取消回复