Gemini背后的技术秘密,谷歌AI团队如何突破极限? 本文深入探讨了谷歌Gemini AI模型的发展过程及其对未来人工智能的影响。通过分析Gemini的技术挑战与突破,以及其在机器人领域的应用前景,为读者提供了关于下一代AI发展的洞察。 36KR热点 2025年04月29日 11:50 0 点赞 0 评论 82 浏览
OpenAI发布Agent工具包,Manus AI引发全球热议 OpenAI发布全新Agent工具包,引发全球关注。与此同时,国产AI Agent产品Manus也崭露头角,但面临国内外市场反应不一的挑战。本文从技术复现、开源项目及未来发展趋势等方面,全面解析AI Agent领域的最新动态。 36KR热点 2025年03月12日 19:10 0 点赞 0 评论 114 浏览
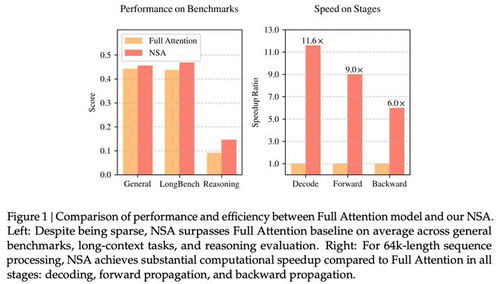
DeepSeek NSA技术:低成本高效率的AI推理革命 DeepSeek推出的NSA技术是一种硬件对齐且原生可训练的稀疏注意力机制,专为超快速长上下文训练与推理设计。该技术通过动态分层稀疏策略、粗粒度token压缩和细粒度token选择等核心组件,在降低成本的同时保持高性能,为AI领域带来了一场真正的降本增效革命。 IT热点 2025年02月19日 05:23 0 点赞 0 评论 92 浏览
OpenAI即将发布o3、o4-MINI和GPT-5,未来人工智能将如何改变我们的生活? 作为一名科技爱好者,他密切关注着OpenAI的最新动态。近日,OpenAI宣布将在数周内发布o3、o4-MINI,并在未来几个月内推出GPT-5模型。这让他感到无比兴奋,同时也引发了他对人工智能未来发展潜力的深刻思考。通过深入研究这些新模型的特点与应用前景,他意识到这将是一场改变世界的革命。 知乎热点 2025年04月10日 22:45 0 点赞 0 评论 77 浏览
Deepseek模型修改后,他的世界变得陌生了 本文以个人视角讲述了deepseek模型修改后带来的影响以及如何应对这些变化,强调了在技术快速发展的背景下,人类创造力和情感的重要性。 简书热点 2025年02月28日 20:35 0 点赞 0 评论 94 浏览
清华DeepSeek使用手册:我的深度学习探索之旅 本文以第一人称视角详细介绍了如何使用清华DeepSeek进行深度学习实践,包括安装配置、常见问题解决以及功能亮点解析等内容,适合对AI感兴趣的读者阅读。 简书热点 2025年02月14日 00:25 0 点赞 0 评论 100 浏览
Grok3与DeepSeek:谁才是AI模型的王者? 本文深入探讨了Grok3与DeepSeek两款AI模型的竞争态势,分析了两者的技术特点、应用场景及未来发展潜力,为读者呈现了一场精彩的技术对决。 贴吧热点 2025年02月18日 17:47 0 点赞 0 评论 95 浏览
DeepSeek-V3-0324发布,这次V3版本有哪些令人惊艳的改进? 作为一名热爱AI技术的人,我深入研究了DeepSeek-V3-0324版本的特性,发现它在性能、代码与数学能力、成本效率以及社区支持等方面都有显著提升。生成速度达到60 TPS,比V2.5快了三倍;同时开源了FP8权重并提供BF16转换脚本,方便社区适配。这些改进让我对AI领域未来充满期待。 知乎热点 2025年03月25日 08:49 0 点赞 0 评论 86 浏览
DeepSeek爆火后,Kimi、豆包等AI产品现状如何? 本文探讨了DeepSeek爆火后,Kimi、豆包等AI产品的现状及面临的挑战,分析了行业未来的发展趋势。 36KR热点 2025年02月20日 15:42 0 点赞 0 评论 95 浏览







 36KR热点
36KR热点 IT热点
IT热点 抖音热点
抖音热点 知乎热点
知乎热点 简书热点
简书热点 贴吧热点
贴吧热点