昨天,IT圈再次被DeepSeek的新技术震撼。作为一名深度关注AI领域的从业者,我第一时间研究了这项名为NSA(Native Sparse Attention)的技术,并且不得不感叹这是一场真正的降本增效革命。
根据官方介绍,NSA是一种硬件对齐且原生可训练的稀疏注意力机制,专为超快速长上下文训练与推理设计。这种技术的核心组件包括动态分层稀疏策略、粗粒度token压缩和细粒度token选择。这些听起来复杂的专业术语背后,其实隐藏着一个非常简单的逻辑——让AI模型在保持高性能的同时,大幅降低计算成本。
为什么NSA如此重要?
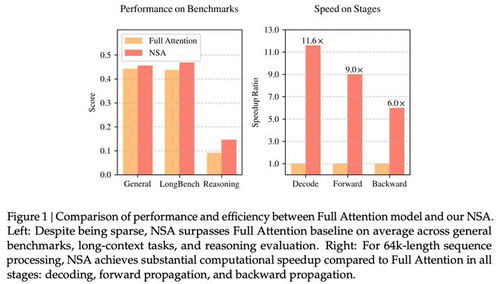
在过去,AI大模型的研发往往伴随着巨额的资金投入。无论是训练还是推理,都需要强大的算力支持,而这笔费用对于许多中小企业来说无疑是难以承受之重。然而,DeepSeek通过推出NSA技术,彻底打破了这一传统观念。他们以“单位算力效能提升10倍”为目标,用极低的成本实现了与行业巨头相媲美的模型性能。
具体来看,DeepSeek V3的训练成本仅为557.6万美元(约合4070万人民币)。这个数字相较于其他同类模型动辄上亿的花费,简直可以用“白菜价”来形容。更重要的是,在降低成本的同时,NSA并没有牺牲性能。相反,它还通过针对现代硬件的优化设计,进一步加快了推理速度。
NSA的实际应用价值
那么,NSA究竟如何实现降本增效呢?答案就在于它的核心技术特点。首先,动态分层稀疏策略允许模型根据任务需求灵活调整计算资源分配,从而避免不必要的浪费。其次,粗粒度token压缩和细粒度token选择则能够有效减少数据处理量,进一步提高运算效率。
这些特性使得NSA不仅适用于科研机构的大规模实验,也能满足企业日常业务中的实际需求。例如,在金融领域,金融科技公司可以利用DeepSeek的低成本、高性能模型开发更加智能、高效的金融产品和服务;在电商领域,京东云等平台也可以借助NSA技术向产业持续输送AI生产力。
未来展望
作为一位长期观察AI行业的观察者,我认为NSA技术的发布标志着AI领域进入了一个全新的阶段。过去,“拼投入”是AI大模型研发的主要模式,但随着DeepSeek这样的创新企业的崛起,我们看到了一条更加可持续的发展道路。
当然,任何新技术都有其局限性。NSA虽然在很多方面表现优异,但在某些特定场景下可能仍然需要进一步优化。不过,这并不妨碍它成为当前最值得关注的技术之一。相信随着时间推移,DeepSeek团队会不断完善NSA,为我们带来更多惊喜。
总之,NSA技术的出现不仅改变了AI模型训练与推理的方式,也为整个行业带来了新的希望。如果你也对这项技术感兴趣,不妨深入研究一下,或许你会发现更多意想不到的可能性。




发表评论 取消回复