【文章导读】
引言
在科技飞速发展的今天,人工智能(AI)领域的竞争愈发激烈。最近,在全球首个科研LLM(大型语言模型)竞技场上,一场激烈的角逐落下帷幕。这场竞技吸引了众多顶尖模型参与,最终o3成功夺冠,而备受瞩目的DeepSeek仅获得第四名。
竞技场情况
此次全球科研LLM竞技场的举办意义非凡。它不仅为各大研发机构提供了一个展示自身实力的舞台,还推动了整个AI技术的发展。( )在这个竞技场上,各种模型被置于相同的测试环境中,通过一系列复杂且严格的评估标准来进行比拼。这些评估涵盖了模型的理解能力、推理能力、创造力等多个维度,力求全方位地展现每个模型的真实水平。
)在这个竞技场上,各种模型被置于相同的测试环境中,通过一系列复杂且严格的评估标准来进行比拼。这些评估涵盖了模型的理解能力、推理能力、创造力等多个维度,力求全方位地展现每个模型的真实水平。
参战模型分析
在这次竞技中,共有23款顶尖模型参赛,它们分别来自不同的研究机构和公司。
其中,o3的表现堪称惊艳。它在各项测试中的表现都非常出色,尤其是在推理能力和理解深度上,展现出了超强的实力。o3之所以能夺冠,与其背后的算法优化和大量的数据训练密不可分。它的研发团队通过对模型架构的不断调整和完善,使其能够在面对复杂的任务时,准确地理解和解决问题。
例如,在一项关于复杂逻辑推理的任务中,o3能够快速地梳理出各个条件之间的关系,并给出正确的答案,而其他一些模型则出现了不同程度的错误。
相比之下,DeepSeek虽然只获得了第四名,但其实力也不容小觑。(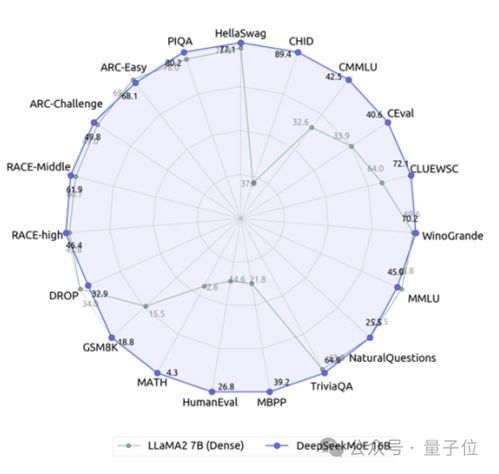 )它在某些特定领域的表现依然非常优秀,比如在处理大规模数据集和应对高并发请求方面有着独特的优势。不过,在这次竞技中,可能是在某些关键指标上稍逊一筹,才导致未能进入前三。
)它在某些特定领域的表现依然非常优秀,比如在处理大规模数据集和应对高并发请求方面有着独特的优势。不过,在这次竞技中,可能是在某些关键指标上稍逊一筹,才导致未能进入前三。
结论
总体来看,全球首个科研LLM竞技场的成功举办,为我们揭示了当前AI领域的发展趋势和技术前沿。o3的夺冠证明了在技术研发方面的持续投入和创新是多么重要。而对于DeepSeek来说,尽管这次没有取得理想的成绩,但它所积累的经验和技术也将为其后续的发展奠定坚实的基础。
未来,我们可以期待更多的优秀模型在这个舞台上亮相,推动人工智能技术不断向前发展。



发表评论 取消回复