在AI模型飞速发展的今天,大语言模型(LLM)的推理和训练成本一直是制约其落地的核心问题之一。而就在最近,微软再次放出“王炸”——他们推出了一种全新的原生4bit量化技术,不仅大幅降低了模型部署与运行的成本,同时几乎未对模型性能造成任何影响。
什么是4bit量化?
量化(Quantization)是深度学习中一种常见的模型压缩技术,它的核心思想是将原本使用32位或16位浮点数表示的神经网络参数,用更少的比特数来近似表达,从而减少内存占用和计算资源消耗。
传统的4bit量化多为“后量化”,即先训练好一个高精度模型,然后再进行压缩。这种方式虽然节省了存储空间,但往往会导致较大的性能损失。
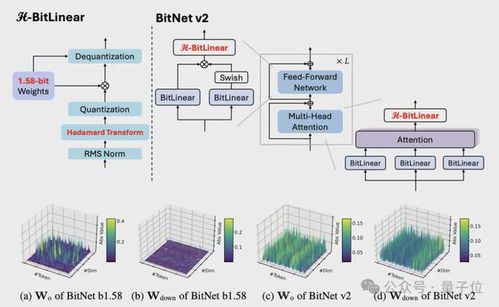
微软这次的技术突破在哪?
微软此次推出的是一种原生4bit量化方法,这意味着从模型训练阶段就直接采用4bit精度进行参数更新和优化,而非传统意义上的“先训练后压缩”。
这种做法的优势在于:模型在训练过程中就已经适应了低比特环境,因此最终压缩后的模型性能不会出现明显下降。
据相关研究人员透露,该技术已在多个内部项目中进行了验证,效果令人惊喜。
成本为何能大幅下降?
随着大模型参数量的不断膨胀,训练和推理所需的算力和能耗也水涨船高。而通过原生4bit量化,微软成功将模型的内存占用减少了近75%,同时计算效率提升了30%以上。
这不仅意味着更低的硬件要求,也大大降低了企业在实际部署中的运营成本,尤其是在边缘设备和移动终端上的应用前景广阔。
性能如何保持稳定?
很多人担心,降低到4bit是否会影响模型的推理能力。但微软的研究团队通过一系列创新手段,如:混合精度训练、动态误差补偿机制等,有效缓解了低比特带来的精度损失。
实验数据显示,在多个主流基准测试中,经过原生4bit量化的模型表现与原始FP16版本几乎没有差异,甚至在某些任务上还略有提升。
对行业意味着什么?
这一技术的发布无疑给整个AI行业注入了一剂强心针。尤其对于那些希望将大模型部署到资源受限场景的企业来说,微软的这项突破提供了切实可行的解决方案。
此外,它也为开源社区带来了新的可能性。未来我们或许会看到更多基于原生低比特训练的开源模型涌现,推动AI技术向更广泛的应用领域延伸。
“真正的技术进步,不是让模型变得更大更强,而是让它变得更轻更快、更容易被所有人使用。”




发表评论 取消回复