文章导读:
在数字化浪潮中,数据流处理变得越来越重要。他第一次接触Kafka时,对这个分布式流处理平台充满了好奇。Kafka是一种高吞吐量、可扩展的消息系统,最初由LinkedIn开发,如今已成为Apache开源项目的一部分。它不仅能够实时处理大规模数据流,还能保证数据传输的可靠性和高效性。
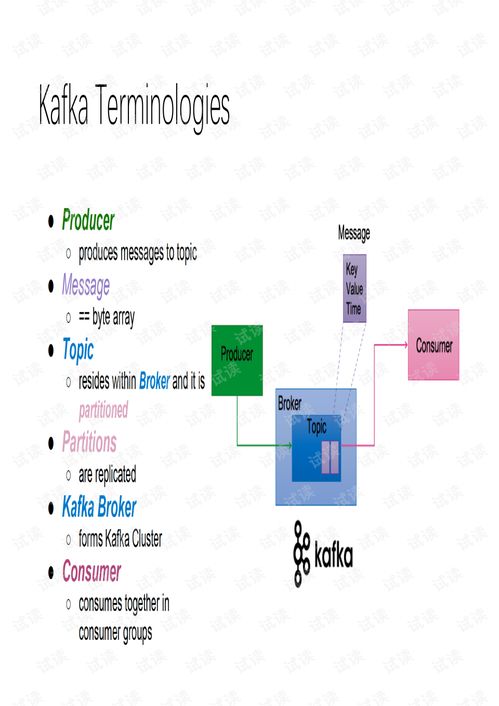
深入研究后,他发现Kafka的核心组件非常关键。首先是Broker,作为Kafka集群中的服务器节点,负责存储和管理消息。其次是Topic,即消息分类的主题,用于将消息组织成不同的类别。Partition是Topic的分区,通过分区可以实现并行处理,从而提高系统的吞吐量。最后是Producer和Consumer,分别负责消息的生产与消费。这些组件共同构成了Kafka的基础架构。
为了更好地理解Kafka的工作机制,他决定深入探究其内部运行逻辑。Kafka采用的是发布-订阅模型,Producer将消息发送到指定的Topic,而Consumer则订阅该Topic以接收消息。消息在Partition中按照顺序存储,并通过Offset进行唯一标识。这种设计使得Kafka能够在高并发场景下保持高效的性能。此外,Kafka还支持持久化存储,确保即使在系统故障的情况下,数据也不会丢失。
在实际应用中,Kafka被广泛应用于日志收集、监控数据处理以及实时数据分析等领域。他参与的一个项目中,Kafka被用来处理用户的点击流数据。通过Kafka,他们能够实时捕获用户的行为,并将其传递给下游的分析系统,从而为业务决策提供支持。他还注意到,在大规模分布式系统中,Kafka的水平扩展能力尤为重要。通过增加Broker的数量,可以轻松应对不断增长的数据流量。
总的来说,他对Kafka的理解已经从最初的浅尝辄止发展到了深入掌握。无论是理论知识还是实践经验,都让他深刻体会到Kafka在现代数据处理领域的重要地位。




发表评论 取消回复