在简书平台上,有一个话题引发了广泛讨论——决策树的最终构建。今天,让我们跟随一位热爱数据科学的朋友的脚步,一起深入了解这一过程。
这位朋友最初接触决策树时,感到既兴奋又迷茫。兴奋的是,决策树作为一种直观且强大的机器学习算法,能够帮助解决实际问题;迷茫的是,如何将理论转化为实践?带着这些问题,他开始了探索之旅。
一、初识决策树
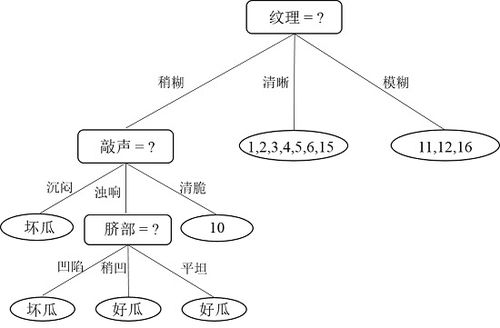
决策树是一种基于树形结构进行分类或回归分析的方法。它通过递归地选择最佳特征分裂节点,从而形成一棵树。在这个过程中,信息增益、基尼系数等指标起到了关键作用。
我们的朋友首先学习了信息增益的概念。简单来说,信息增益衡量的是某个特征对数据集纯度提升的程度。通过计算每个特征的信息增益,可以确定哪个特征最适合用来划分数据。
二、实践中的挑战
然而,当真正动手实现时,困难接踵而至。首先是数据预处理阶段。原始数据往往存在缺失值、异常值等问题,需要进行清洗和转换。他花费大量时间研究各种数据处理技巧,比如用均值填补缺失值、标准化数值范围等。
其次是模型调参环节。为了找到最优参数组合,他尝试了网格搜索、随机搜索等多种方法。经过反复试验,终于得到了一个较为理想的模型。
三、收获与感悟
完成整个项目后,他深刻体会到,决策树不仅仅是一个算法工具,更是一种思维方式。它教会我们如何从复杂的数据中提取有用信息,并以清晰的方式呈现出来。
此外,他还发现,在实际应用中,决策树常常与其他算法结合使用,例如随机森林、梯度提升决策树等。这些集成方法能够在保持可解释性的同时,进一步提高预测性能。
最后,他总结道:“学习决策树的过程虽然充满挑战,但也带来了巨大的成就感。每一次克服困难都让我更加坚信,只要坚持不懈,就一定能够掌握这项技能。”




发表评论 取消回复