在大数据的世界里,Apache Hive无疑是一颗璀璨的明星。作为一名初学者,我曾经对Hive的性能调优感到困惑不已。然而,通过不断学习与实践,我逐渐掌握了一些关键技巧,现在就和大家分享我的心得。
一、了解Hive的基本原理
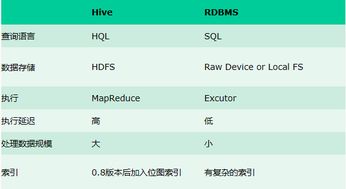
要想优化Hive查询性能,首先得清楚它是如何工作的。Hive本质上是一个数据仓库工具,它将SQL查询转换为MapReduce任务来执行。因此,任何影响MapReduce效率的因素都会间接影响Hive的表现。
二、合理设置参数
参数配置是提升性能的重要手段之一。例如,可以通过调整hive.exec.reducers.bytes.per.reducer参数来控制Reducer的数量。如果设置得太少,可能会导致单个Reducer处理的数据量过大;而设置得太多,则会增加调度开销。经过多次试验,我发现将该值设为1GB左右通常可以获得较好的效果。
三、选择合适的存储格式
不同的文件格式对查询性能也有很大影响。TextFile虽然简单易用,但其压缩率低且不支持列式存储。相比之下,ORC(Optimized Row Columnar)格式不仅具备高压缩比,还支持高效的列存访问模式,能够显著加快读取速度。在我的项目中切换到ORC后,查询时间减少了将近一半。
四、利用分区与分桶技术
对于大规模数据集来说,分区和分桶是非常有效的组织方式。通过按某些字段进行分区,可以大幅减少扫描的数据量;而分桶则有助于实现采样和join操作的优化。记得有一次,我们的报表生成任务耗时过长,后来引入了分桶机制,问题迎刃而解。
五、避免常见误区
最后,还要注意规避一些常见的错误做法。比如不要盲目增加并发度,因为这可能导致资源争抢反而拖慢整体进度。另外,在写复杂查询时尽量分解成多个小步骤,这样既能提高可维护性,又能便于定位性能瓶颈。
以上就是我在使用Apache Hive过程中总结的一些经验教训。当然,理论终究需要结合实际才能发挥最大价值,希望大家都能根据自身业务特点灵活运用这些方法,共同探索更高效的大数据分析之道。




发表评论 取消回复