作为一名数据爱好者,在学习Pandas的过程中,总是绕不开一个强大的功能——groupby。今天,让我们一起深入探讨如何通过groupby和agg函数让数据分析变得轻松高效。
在日常的数据处理中,我们经常需要对数据进行分组统计,比如按地区、时间或类别汇总数据。而Pandas中的groupby方法正是为此量身定制的利器。那么,groupby到底是什么?简单来说,它是一种“拆分-应用-合并”的过程。首先将数据按照指定条件拆分成多个子集,然后对每个子集应用特定操作,最后将结果重新组合起来。
一、初识groupby
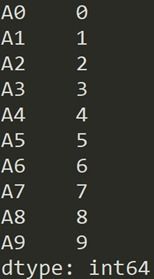
假设有一个包含销售数据的表格,其中记录了不同地区的销售额。如果想计算每个地区的总销售额,就可以使用如下代码:
import pandas as pd
# 创建示例数据
data = {
'地区': ['北区', '南区', '东区', '西区', '北区'],
'销售额': [100, 200, 150, 300, 50]
}
df = pd.DataFrame(data)
# 使用groupby计算每组的总销售额
result = df.groupby('地区')['销售额'].sum()
print(result)这段代码会输出每个地区的总销售额,非常直观且高效。
二、agg函数的魅力
虽然groupby已经很强大了,但当我们需要同时计算多个统计指标时,手动编写代码可能会显得繁琐。这时候,agg函数就派上了用场。它可以一次性完成多种聚合操作,大大简化了代码逻辑。
例如,如果我们不仅想知道每个地区的总销售额,还想了解平均值和最大值,可以这样写:
result = df.groupby('地区')['销售额'].agg(['sum', 'mean', 'max'])
print(result)运行后,你会得到一个包含总和、均值和最大值的多列结果表,是不是很方便?
三、灵活运用自定义函数
除了内置的聚合函数外,agg还支持自定义函数,满足更复杂的业务需求。比如,我们可以定义一个函数来计算销售额的标准差:
def custom_std(x):
return x.std()
result = df.groupby('地区')['销售额'].agg([custom_std])
print(result)通过这种方式,你可以根据实际问题设计专属的聚合逻辑。
四、实战案例分享
为了更好地理解groupby和agg的应用场景,这里分享一个真实案例。假设你是一家电商公司的数据分析师,需要分析用户购买行为。你的任务是统计每位用户的订单数量、总消费金额以及平均单笔消费额。以下是实现步骤:
- 加载数据并检查字段结构。
- 使用groupby按用户ID分组。
- 调用agg函数分别计算订单数(count)、总金额(sum)和平均值(mean)。
最终生成的结果表可以直接用于制作报告或进一步挖掘价值。
五、总结与展望
通过本文的学习,相信你已经掌握了groupby和agg的核心用法。它们不仅是数据分析的基础工具,更是提升工作效率的重要手段。未来,随着数据量的不断增长,掌握这些技能将帮助你在职场中脱颖而出。所以,不妨从现在开始练习吧!



发表评论 取消回复