作为一名数据库爱好者,最近我对MySQL的MVCC(Multi-Version Concurrency Control,多版本并发控制)机制进行了深入的学习。今天,我想和大家分享一下我的心得和体会。
什么是MVCC?
在开始之前,我们先来了解一下MVCC的概念。简单来说,MVCC是一种用于提高数据库并发性能的技术。它的核心思想是通过保存数据的历史版本,让读写操作可以同时进行而不互相干扰。
MVCC的工作原理
在我的学习过程中,我发现MVCC的工作原理其实并不复杂。它主要依赖于隐藏字段和事务ID来实现:
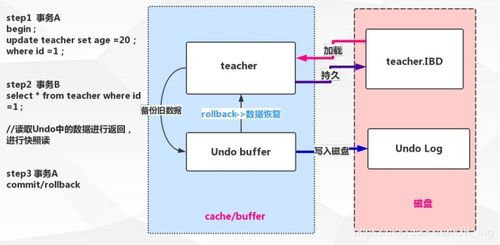
- 隐藏字段:每一条记录都有两个隐藏字段——trx_id和roll_pointer。trx_id表示这条记录是由哪个事务插入的,而roll_pointer则指向这条记录的上一个版本。
- 事务ID:每个事务在开始时都会被分配一个唯一的事务ID。这个ID会用来判断当前事务是否可以看到某条记录。
通过这种方式,当多个事务同时访问同一条记录时,MVCC可以通过比较事务ID和隐藏字段的值,决定是否需要返回该记录的历史版本。
为什么需要MVCC?
在我实际操作MySQL的过程中,我深刻体会到了MVCC的重要性。试想一下,如果没有MVCC,当多个事务同时对同一张表进行读写操作时,就可能出现锁等待甚至死锁的情况。这不仅会降低系统的性能,还可能影响用户体验。
MVCC的出现很好地解决了这个问题。它允许读写操作并行执行,从而提高了数据库的整体吞吐量。
MVCC的实际应用
为了更好地理解MVCC的实际应用,我做了一个小实验。我创建了一张简单的用户表,并模拟了多个事务对这张表进行并发操作的场景。
在这个实验中,我观察到以下几个关键点:
- 当一个事务读取某条记录时,MVCC会根据当前事务的ID和记录的隐藏字段,决定是否返回该记录的最新版本或历史版本。
- 当一个事务更新某条记录时,MVCC并不会直接修改原记录,而是创建一个新的版本,并将旧版本保留下来。
- 通过这种方式,即使有其他事务正在读取这条记录,也不会受到影响。
通过这个实验,我对MVCC的工作原理有了更加直观的理解。
总结与展望
经过这次深入的学习,我对MySQL的MVCC机制有了全新的认识。它不仅是一项重要的技术,更是解决数据库并发问题的关键所在。
未来,我希望能够继续深入研究数据库领域的其他核心技术,不断提升自己的技术水平。如果你也对数据库感兴趣,不妨一起来探索吧!



发表评论 取消回复