在简书平台上,最近有个热门话题吸引了小王的注意——“教3妹学MQ”。作为一个资深的技术爱好者,小王决定亲自上阵,用通俗易懂的方式给3妹讲解Kafka的工作流程。
一、初识Kafka
小王首先告诉3妹,Kafka是一种高吞吐量的分布式消息系统,常用于构建实时数据管道和流式应用。它由Apache开发并开源,广泛应用于大数据处理领域。
为了帮助3妹更好地理解,小王举了一个生活中的例子:想象一下,你在一家餐厅点餐,服务员记录你的订单后,将信息传递给厨房。这个过程就像Kafka在系统中扮演的角色,负责高效地传输数据。
二、Kafka的核心组件解析
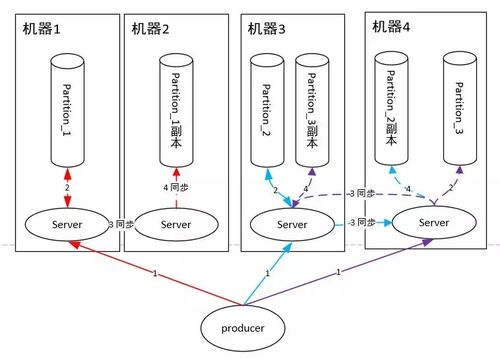
接下来,小王详细介绍了Kafka的核心组件:
- Producer(生产者):负责创建消息并将它们发送到Kafka集群。
- Consumer(消费者):从Kafka集群中读取消息并进行处理。
- Broker(代理服务器):Kafka集群中的节点,负责存储和管理消息。
- Topic(主题):消息分类的逻辑概念,生产者向特定主题发送消息,消费者订阅这些主题。
- Partition(分区):每个主题可以分为多个分区,以提高并发性和扩展性。
三、Kafka的工作流程详解
为了让3妹彻底掌握Kafka的工作原理,小王一步步拆解了它的运行机制:
- 生产者将消息发送到指定的Topic。
- Kafka会根据分区策略将消息分配到相应的Partition。
- 消息被追加到Partition的日志文件末尾,并分配一个唯一的Offset(偏移量)。
- 消费者从Partition中拉取消息,并通过Offset跟踪消费进度。
小王还特别强调了Offset的重要性,它是消费者用来标记已消费消息的关键标识。
四、实践中的注意事项
最后,小王提醒3妹,在实际使用Kafka时需要注意以下几点:
- 合理设置分区数量,避免过多或过少影响性能。
- 监控Kafka集群的状态,确保其稳定运行。
- 定期清理过期消息,防止磁盘空间不足。
- 优化消费者组配置,提升消息处理效率。
通过这次深入浅出的讲解,3妹对Kafka的工作流程有了清晰的认识。小王也感到非常欣慰,因为他不仅帮助了3妹,还巩固了自己的知识体系。如果你也想学习Kafka,不妨跟着小王的步伐,一起探索这个强大的消息系统吧!




发表评论 取消回复