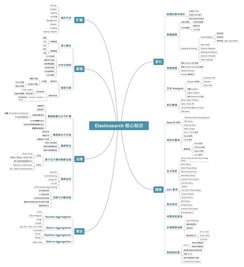
在简书平台上,最近一篇关于Elasticsearch的文章引起了广泛关注。作为一名初学者,他决定深入研究一下这个强大的搜索引擎,并分享自己的学习心得。今天,我们就跟随他的脚步,一起探索Elasticsearch数据的完整读写流程。
一、什么是Elasticsearch
Elasticsearch是一个开源的分布式搜索和分析引擎,它基于Apache Lucene构建。简单来说,Elasticsearch可以高效地存储海量数据,并支持快速查询和分析。对于那些需要处理大规模数据集的应用场景,Elasticsearch无疑是最佳选择之一。
二、数据写入流程
1. 创建索引:首先,我们需要创建一个索引来存储数据。索引类似于数据库中的表,是数据的基本组织单位。通过定义映射(Mapping),我们可以指定字段类型和其他属性。
2. 添加文档:接下来,将数据以JSON格式插入到索引中。每条记录称为一个文档,每个文档都有唯一的ID标识。
3. 批量写入:如果要一次性导入大量数据,可以使用Bulk API来提高效率。这种方法能够显著减少网络开销并加快写入速度。
三、数据读取流程
1. 简单查询:通过GET请求可以直接获取特定文档的内容。
2. 复杂查询:利用DSL(Domain Specific Language)编写更复杂的查询条件,例如过滤、排序、分页等功能都可以实现。
3. 聚合分析:除了基本的检索功能外,Elasticsearch还提供了强大的聚合能力,可以帮助我们对数据进行统计和分析。
四、实际案例应用
为了更好地理解上述理论知识,他结合自己的项目经验,设计了一个简单的应用场景:假设我们要构建一个电商网站的商品搜索引擎。在这个例子中,商品信息被存储在Elasticsearch中,用户可以通过关键词搜索相关商品,并查看价格区间分布等信息。
具体步骤如下:
- 将所有商品数据导入Elasticsearch;
- 根据用户输入的关键字生成查询语句;
- 返回匹配结果列表以及相应的统计数据。
通过这个过程,他不仅巩固了所学的知识点,还发现了一些优化性能的小技巧,比如合理设置分片数量、调整刷新间隔等参数。
五、总结与展望
经过一段时间的学习实践,他对Elasticsearch有了更加深刻的认识。虽然刚开始接触时可能会觉得有些复杂,但只要掌握好核心概念和操作方法,就能够轻松应对大多数实际问题。未来,他还计划继续深入研究Elasticsearch的高级特性,如跨集群搜索、机器学习插件等内容。



发表评论 取消回复