在当今的互联网开发领域,随着业务规模的不断扩大,数据库的性能和扩展性问题逐渐成为系统瓶颈。尤其是在面对海量数据和高并发请求时,传统的单库单表架构已经难以满足需求。作为一名开发者,我也不例外,在项目中遇到了类似的挑战。幸运的是,我发现了Sharding-JDBC,一款强大的分库分表工具,它不仅帮助我解决了这些问题,还让我对分布式数据库有了更深的理解。
一、为什么选择 Sharding-JDBC?
在我接触 Sharding-JDBC 之前,也曾尝试过其他分库分表方案,比如 MyCat 和 TDDL。这些工具虽然功能强大,但在实际使用中存在一些问题。例如,MyCat 的部署较为复杂,且对 SQL 的支持不够完善;TDDL 虽然轻量级,但它的社区活跃度较低,遇到问题时很难找到解决方案。而 Sharding-JDBC 则不同,它不仅提供了丰富的功能,还具有以下优势:
- 简单易用:Sharding-JDBC 是一个基于 JDBC 的 Java 库,可以直接嵌入到应用程序中,无需额外的中间件或代理层。这意味着我们可以像使用普通 JDBC 一样操作数据库,几乎不需要修改现有代码。
- 高性能:Sharding-JDBC 通过将查询语句解析为多个子查询,并行执行,大大提高了查询效率。同时,它还支持读写分离、数据加密等功能,进一步提升了系统的性能和安全性。
- 灵活的分片策略:Sharding-JDBC 支持多种分片算法,如哈希分片、范围分片、精确分片等。我们可以根据业务需求选择合适的分片策略,确保数据分布均匀,避免热点问题。
- 完善的社区支持:Sharding-JDBC 拥有一个非常活跃的开源社区,官方文档详细,遇到问题时可以轻松找到解决方案。此外,社区还会定期发布新版本,修复已知问题并添加新功能。
二、Sharding-JDBC 的核心功能
了解了 Sharding-JDBC 的优势后,接下来我们来看看它的核心功能。Sharding-JDBC 提供了丰富的功能模块,涵盖了分库分表、读写分离、数据加密等多个方面。以下是我在项目中常用的一些功能:
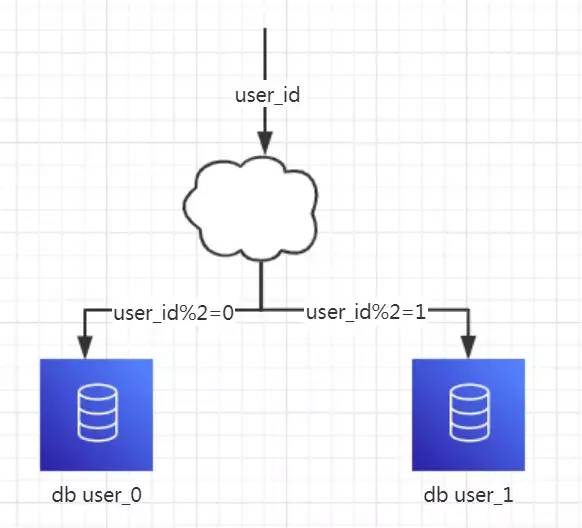
- 分库分表:这是 Sharding-JDBC 最基本也是最重要的功能。通过配置分片规则,我们可以将数据分散到多个数据库和表中,从而提高系统的水平扩展能力。例如,在我的项目中,我们将用户表按照用户 ID 进行哈希分片,每个分片对应一个独立的数据库实例。这样不仅可以缓解单个数据库的压力,还能提高查询效率。
- 读写分离:为了提高系统的读取性能,Sharding-JDBC 支持读写分离。我们可以为每个数据库配置多个只读从库,主库负责写操作,从库负责读操作。这样可以在不影响写性能的前提下,大幅提高读取速度。在我的项目中,我们为每个分片配置了两个从库,读取性能提升了近 50%。
- 数据加密:在某些敏感场景下,数据的安全性至关重要。Sharding-JDBC 提供了内置的数据加密功能,支持对字段进行加密存储。例如,我们对用户的密码字段进行了加密处理,确保即使数据库被攻破,攻击者也无法直接获取用户的明文密码。
- SQL 解析与优化:Sharding-JDBC 内置了强大的 SQL 解析引擎,能够自动识别并优化复杂的查询语句。它会根据分片规则将查询语句拆分为多个子查询,并行执行,最后将结果合并返回给应用。这不仅提高了查询效率,还减少了开发人员的手动优化工作。
三、Sharding-JDBC 的实战案例
在了解了 Sharding-JDBC 的功能后,接下来我将分享一个真实的实战案例,展示它是如何帮助我们解决实际问题的。
在我参与的一个电商项目中,随着用户数量的快速增长,订单表的数据量迅速膨胀,导致查询性能急剧下降。特别是当用户查询历史订单时,系统响应时间明显变长,用户体验大打折扣。为了解决这个问题,我们决定引入 Sharding-JDBC 进行分库分表。
首先,我们对订单表进行了分析,发现订单数据主要集中在最近几个月,而历史订单的数据访问频率较低。因此,我们决定采用时间范围分片的策略,将订单表按月份进行分片。具体来说,我们将每个月的订单数据存储在一个独立的分片中,每个分片对应一个数据库实例。这样不仅可以缓解单个数据库的压力,还能提高查询效率。
其次,为了进一步提升读取性能,我们启用了读写分离功能。我们为每个分片配置了一个主库和两个从库,主库负责写操作,从库负责读操作。经过测试,读取性能提升了近 50%,系统响应时间显著缩短。
最后,考虑到订单数据的安全性,我们对敏感字段(如用户信息、支付信息)进行了数据加密处理。通过 Sharding-JDBC 的内置加密功能,我们确保了即使数据库被攻破,攻击者也无法直接获取用户的敏感信息。
通过引入 Sharding-JDBC,我们的系统性能得到了显著提升,用户查询历史订单的速度大幅提升,用户体验得到了极大改善。更重要的是,Sharding-JDBC 的灵活性和易用性让我们能够在不改变现有代码结构的情况下,快速实现分库分表,极大地降低了开发成本。
四、Sharding-JDBC 的未来展望
随着业务的不断发展,分布式数据库的需求将会越来越多。作为一款开源的分库分表工具,Sharding-JDBC 在未来的应用场景中有着广阔的前景。目前,Sharding-JDBC 已经成为了阿里巴巴、腾讯等大型互联网公司的重要技术栈之一,这也充分证明了它的可靠性和稳定性。
在我看来,Sharding-JDBC 的未来发展将主要集中在以下几个方面:
- 更强大的分布式事务支持:虽然 Sharding-JDBC 目前已经支持部分分布式事务功能,但在复杂的业务场景下,仍然存在一定的局限性。未来,Sharding-JDBC 将进一步优化分布式事务的实现,提供更加完善的解决方案。
- 更好的云原生支持:随着云计算的普及,越来越多的企业开始将应用迁移到云端。Sharding-JDBC 也将在未来加强与云平台的集成,提供更好的云原生支持,帮助企业更轻松地构建分布式数据库系统。
- 更智能的分片策略:目前,Sharding-JDBC 的分片策略主要依赖于开发人员的手动配置。未来,Sharding-JDBC 将引入更多智能化的分片算法,能够根据数据的访问模式自动调整分片策略,进一步提升系统的性能和可维护性。
总之,Sharding-JDBC 不仅是一款优秀的分库分表工具,更是我们在分布式数据库领域的得力助手。通过它,我们不仅可以轻松应对海量数据和高并发请求,还能在保证系统性能的同时,确保数据的安全性和可靠性。相信在未来,Sharding-JDBC 将继续为我们带来更多惊喜,助力更多的开发者构建高效、稳定的分布式系统。
发表评论 取消回复