导读:本文将从多个角度解析 DeepSeek R1 的最新升级、与竞品模型的对比、用户反馈以及未来展望。点击以下标签可快速跳转至对应段落:
DeepSeek R1 升级亮点:小改动带来大提升
就在昨天(5月28日),DeepSeek 官方宣布其 R1 模型已完成小版本试升级。虽然只是一个小版本更新,但依然引发了广泛关注。
此次升级主要集中在推理速度优化和多模态交互能力增强上。官方表示,用户可以通过访问网页端、APP 或小程序进行测试,API 接口及使用方式保持不变,极大降低了用户的迁移成本。
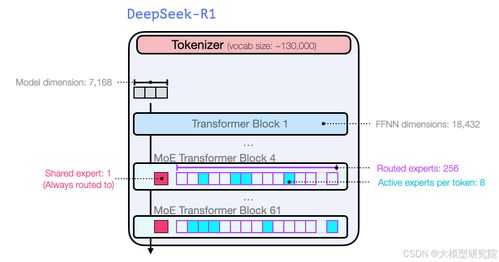
值得一提的是,这次升级并未对训练数据进行大规模调整,而是通过算法层面的微调提升了整体性能。这说明 DeepSeek 团队在模型压缩和效率优化方面已经具备了相当成熟的技术。
与 Gemini、GPT 等模型的横向对比
在全球 AI 大模型竞争日益激烈的背景下,DeepSeek R1 的升级自然也引起了行业内外对其与 Google Gemini、OpenAI GPT 系列模型的对比讨论。
“DeepSeek 正在用更少的资源做更多的事。”——某 AI 领域资深工程师
根据新智元此前报道,虽然 DeepSeek-R1 的一些实现细节尚未完全开源,但已有不少研究团队尝试复现其训练流程,并取得了不错的效果。而与此同时,Google 在最近的 I/O 大会上推出了Gemini 2.5 Pro,号称是目前世界上最智能的 AI 模型,预计将在6月正式上线。
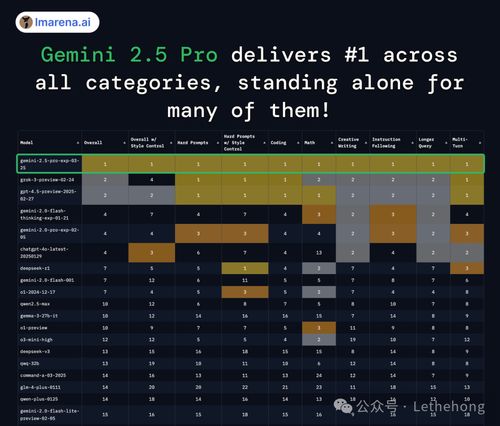
从参数量和训练成本来看,DeepSeek 显然走的是高性价比路线。以 DeepSeek-V3 为例,其总训练成本仅为 557.6 万美元,远低于 GPT-4o 等模型的数亿美元级别。
用户真实体验分享:轻量部署成关键优势
据澎湃新闻发布的信息,DeepSeek V3 模型曾在3月底完成一次重要升级,支持在消费级硬件上运行,这一特性在开发者群体中反响热烈。
笔者亲自测试后发现,在本地部署的情况下,R1 模型表现出了良好的兼容性和响应速度。特别是在处理中文文本任务时,无论是写作辅助还是逻辑推理,都能给出较为准确的答案。
一位来自极客网的读者告诉笔者:“以前我只能在云端跑这些大模型,现在在家里的笔记本就能用了,简直是降本增效的一大利器!”
未来 AI 技术趋势:轻量化、开放化仍是主旋律
从 DeepSeek 的一系列动作可以看出,当前 AI 行业正朝着轻量化部署和开源共享的方向发展。
光明网曾指出,随着越来越多企业和开发者加入到开源社区中来,像 DeepSeek 这样的国产大模型正在逐步打破国外巨头的技术垄断。尤其是在中文场景下的应用,DeepSeek 已经展现出了不俗的竞争力。
此外,IT之家发布的《DeepSeek 玩法攻略》也说明了该模型在实际应用中的广泛性。无论是提示词编写技巧,还是本地部署方案,都为普通用户提供了极大的便利。
可以预见,未来的 AI 发展不会仅仅依赖于更大规模的模型,而是会更加注重实用性、可移植性和生态建设。



发表评论 取消回复