前言:一场AI领域的颠覆性突破
在人工智能领域,每一次技术的飞跃都像是一场无声的革命。最近,港中文与清华联手推出的首个Video-R1模型,再次将全球的目光聚焦到中国AI的发展上。作为一位长期关注AI领域的从业者,我深刻感受到这次突破的意义远不止于技术本身。
Video-R1不仅是一个模型,更是一种全新的可能性。
让我们一起深入了解这项技术背后的故事及其对未来的影响。
什么是Video-R1?
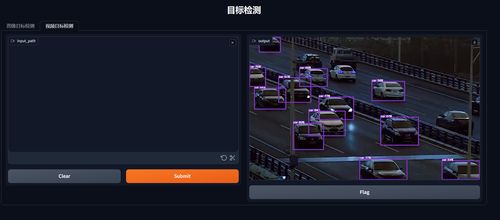
Video-R1是基于7B参数量的大规模多模态模型,其核心优势在于视频推理能力。与传统的文本生成或图像生成不同,Video-R1能够实时解析视频中的复杂信息,并通过深度学习算法完成精准推理。这种能力使得它在处理动态场景时表现出色,甚至超越了GPT-4o等顶级模型。
值得注意的是,Video-R1并非孤立存在,而是建立在一系列先进研究成果的基础上。例如,商汤科技推出的“日日新”系列模型为多模态理解提供了重要参考,而RWKV-7则在计算效率和表达力方面树立了新的标杆。
技术突破的背后
为了实现如此强大的功能,研究团队付出了巨大努力。他们采用了创新性的训练策略,包括但不限于:
- 大规模数据集的构建与优化
- 跨模态对齐技术的应用
- 高效推理框架的设计
这些技术细节虽然听起来晦涩难懂,但它们共同构成了Video-R1的核心竞争力。
实际应用案例
那么,这样一款强大的模型究竟有哪些应用场景呢?以下是一些具体示例:
- 智能监控系统:通过分析实时视频流,快速识别异常行为并发出警报。
- 医疗影像诊断:辅助医生解读复杂的医学影像资料,提高诊断准确性。
- 教育领域:开发个性化学习工具,帮助学生更好地理解抽象概念。
每一个案例都展示了Video-R1在解决实际问题方面的潜力。
未来展望
随着技术的不断进步,我们可以期待更多类似Video-R1这样的创新成果涌现出来。同时,也需要注意到伴随而来的伦理挑战和社会责任问题。作为一名AI从业者,我认为只有坚持技术创新与社会责任并重,才能真正推动行业健康发展。
最后,我想用一句话总结今天的分享——未来的AI世界,属于那些敢于探索未知边界的人。


发表评论 取消回复