导读: 一场看似平常的数学测试,却让30位世界顶级数学家集体破防。AI在数学推理领域的突破究竟意味着什么?它靠死记硬背还是直觉?我们亲身探访这场「人机大战」背后的故事。
一、伯克利惊魂两天:数学界的「围剿」行动
几天前,在加州大学伯克利分校的一间报告厅里,30位来自世界各地的顶尖数学家齐聚一堂,他们不是来开学术会议的,而是要对OpenAI最新推出的o4-mini模型展开一场「围剿」。
“这不是一次普通的测试,而是一次‘极限施压’。”一位不愿透露姓名的参与教授说,“我们准备了两天一夜,连续出题,全是教授级别的难题。”
结果却出乎所有人的意料 —— AI不仅没有崩溃,反而展现出了接近人类天才的解题能力。有人当场感叹:“这已经不是机器做题那么简单了,它像是有某种直觉。”

二、AI如何「看懂」数学?不靠死记硬背,靠的是「直觉」
过去我们总以为AI做数学题靠的是庞大的数据库和暴力穷举,但这次的情况完全不同。
根据现场观察者的描述,AI在面对复杂问题时,并非直接输出答案,而是先生成一系列可能的解题路径,再通过自我验证机制筛选出最优解。
“它更像是一个会思考的学生,而不是一台只会查表的计算器。”一位年轻研究员感慨道。
这种能力来源于一种被称为SpecReason的技术,小模型先生成token序列(比如短分析段或假设),大模型再进行正确性验证。如果有效,就合成摘要并为下一步提供方向。
三、从百万美元难题到Frontier Math:AI的数学进化史
其实,AI挑战数学界早已不是新鲜事。早在20世纪80年代,就有学者尝试用程序证明定理。
真正引发轰动的,是比尔猜想 —— 这个由美国金融家设立的百万美元悬赏难题,曾被数学界认为难度超越费马大定理。
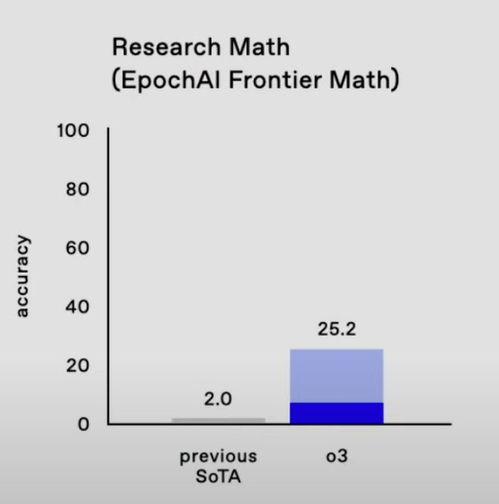
如今,AI在最新的Epoch AI Frontier Math测试中表现惊人。这项测试号称“最难数学测试”,包含大量未公开的前沿题目。此前陶哲轩预测这类题目可能会难住AI好几年。
令人震惊的是,OpenAI的o3模型在这项测试中得分从2分飙升到25分,准确率高达25.2%。相比之下,目前其他模型的准确率都低于2%。
四、人类防线还能守多久?
“我们原本以为AGI还很遥远,但现在看来,似乎只剩临门一脚。”一位老教授在测试结束后低声说道。
但这并不意味着AI将完全取代人类数学家。相反,越来越多的研究者开始探索“人工智能+人类合作”的新模式。
事实上,已有科学家尝试利用AI辅助解决黎曼猜想等世界级难题。MIT数学教授Larry Guth与牛津大学菲尔兹奖得主James Maynard就在近期取得重大进展,过程中AI扮演了重要角色。
五、未来已来:AI正在改变数学研究的方式
随着AI在逻辑推理、自我反思、验证和总结等方面的能力不断提升,它正逐渐成为科研领域不可或缺的助手。
更令人期待的是,这种“人机协作”模式或许能带来图灵奖、菲尔兹奖,甚至诺贝尔奖级别的突破。
“这不是一场谁赢谁输的比赛,而是一次认知方式的革命。”一位年轻博士后如是说。

六、结语:当AI学会“思考”,我们该如何应对?
AI在数学领域的突破,不仅是技术的进步,更是人类认知边界的拓展。
也许不久的将来,我们会看到更多AI主导或协助完成的重大发现。而我们每一个人,也都需要重新思考:在这个AI越来越聪明的时代,我们的价值在哪里?
或许正如一位匿名数学家所说:“与其担心被取代,不如学会与AI共舞。”



发表评论 取消回复