4月29日凌晨,阿里巴巴正式发布通义千问Qwen3系列模型,这一消息迅速在科技圈炸开锅。 作为国内首个“混合推理模型”,Qwen3不仅将“快思考”与“慢思考”集成进同一个模型,还全面开源,成为全球最强开源模型之一。那么,Qwen3究竟是如何做到这一点的?它的训练方法又有哪些独特之处?今天,我们就来聊聊这个话题。
混合推理模型的架构革新
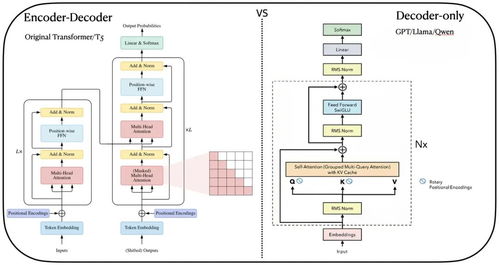
传统的大语言模型(LLM)通常采用单一的推理模式,要么是快速响应的“非思考模式”,要么是深度推理的“思考模式”。而Qwen3则打破了这种界限,首次将两种模式融合在一个模型中。
“这就像给AI装上了两个大脑,一个负责闪电反应,另一个则擅长深度分析。”一位技术专家评论道。
根据36kr报道,Qwen3通过引入结构化的思维模板库和基于思维模板轨迹奖励的层次化强化学习算法,实现了高效推理。这意味着,在面对复杂问题时,Qwen3可以像人类一样分步推理,逐步验证答案的准确性。
训练阶段的秘密武器
Qwen3的成功并非偶然。据极客公园报道,该模型预训练数据量高达36万亿token,并在后训练阶段进行了多轮强化学习。这种训练方式不仅提升了模型的泛化能力,也增强了其对复杂任务的处理效率。
特别是在强化学习阶段,Qwen3通过解题反馈不断优化自己的推理路径。正如ZAKER所指出的那样,早期融合和晚期融合模型在验证损失方面表现相当,但早期融合模型所需参数更少,意味着更高的训练效率。
性能表现与优化策略
在实际测试中,Qwen3展现出了惊人的性能提升。例如,Kevin-32B相比QwQ-32B和单轮训练模型有显著优势。随着优化步骤从4个增加到8个,差距进一步扩大,表明Qwen3具备更强的学习潜力。
此外,Qwen3主打“思考更深、行动更快”的理念,使其在构建AI应用时更具优势。无论是文本生成、逻辑推理还是多模态任务,Qwen3都能游刃有余地应对。
开源背后的深意
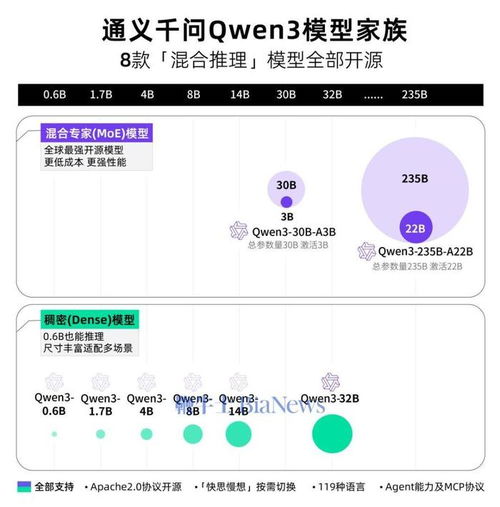
最令人振奋的是,Qwen3系列模型全面开源。这意味着开发者可以自由使用、修改甚至重新训练这些模型,推动AI技术的发展。
正如扬子晚报所说,Qwen3的开源不仅是技术上的突破,更是对中国乃至全球AI生态的一次重大贡献。它降低了AI开发的门槛,让更多人能够参与到这场技术革命中来。
未来展望:AI应用的新可能
随着Qwen3的发布,我们正站在一个全新的起点上。未来的AI应用将不再局限于单一任务,而是能够在多种场景下灵活切换,提供更加智能的服务。
从金融界的报道来看,Qwen3已经在多个领域展现出巨大的潜力。无论是企业级应用还是个人助手,Qwen3都有望成为下一代AI的核心驱动力。
总之,Qwen3的出现标志着大模型技术进入了一个新的阶段。它不仅提升了模型的推理能力,也为AI的发展开辟了更多可能性。未来,我们可以期待看到更多基于Qwen3的创新应用,真正实现“思考更深、行动更快”的目标。





发表评论 取消回复